
この記事でわかること
- Google Colabと
face_recognitionライブラリで、共有フォルダから家族の写った写真だけを自動抽出する手順 - 抽出精度を左右する
TOLERANCEのチューニング方法(実際に3回試した記録つき) - 参照写真の選び方で結果がどれくらい変わるか
背景・きっかけ
先日参加したイベントの写真が、後日Google Driveで一括共有されました。枚数を見たら全部で235枚、1枚あたり5MB前後。我が家が写っているのは、イベント規模からみてせいぜい10枚もあればいい方です。
素敵な時間をいただけたばかりか、思い出の写真まで高画質でいただけるのはありがたい限りです。一方で、育児の合間を縫って大量の写真を1枚ずつ確認するのはちょっと大変。最初に思いついたのは「全部ダウンロード→Googleフォトの顔フィルターで絞り込み→不要分を削除」という流れでした。ただ1枚5MBの写真を235枚も取り込むとストレージを大きく消費する割にリターンが薄く、もう少しスマートにやりたいところです。
そこで Google Colab 上で face_recognition を動かし、Drive上の写真を直接スキャンして家族が写ったものだけ別フォルダにコピーする方法を試しました。結論から言うと、3回のチューニングを経て 235枚→57枚(うち正解12/14枚) まで絞り込めました。元の235枚を全部見るよりも、57枚を眺める方が圧倒的に楽だったので、最終チェックの負担はかなり軽くなりました。
なぜGoogle Colabを選んだか
私自身、Google Colab を本格的に触ったのは今回が初めてでした。ローカルのMacにPython環境を整えてもよかったのですが、Colabを選んだ理由は3つあります。
① コストがかからない
無料枠だけで今回の処理は十分に完結しました。face_recognition は内部で dlib という機械学習ライブラリのビルドが走るため、ローカルだと環境構築でつまずきがちなところを、Colabならブラウザだけで完結します。
② Googleアカウントの連携がスムーズ
今回のように Google Drive 上の写真を扱う場合、Colab はそのままドライブをマウントできるので、共有フォルダのファイルにパスでアクセスできます。OAuth認証もボタン1つです。Drive API キーの発行などは要りません。
③ セキュリティ面でも整理しやすい
face_recognition は内部処理がローカル(=Colabサーバー内)で完結するライブラリなので、顔データが外部APIに送信されることはありません。共有写真も自分の参照写真も、すべてGoogleの環境内に閉じます。普段からGoogleドライブにアップしている写真なので、追加のセキュリティリスクはほぼありません。
環境・前提条件
- Google Drive(共有フォルダにアクセスできるGoogleアカウント)
- Google Colab(ブラウザだけで動くPython環境、無料枠でOK)
- 参照写真として、家族メンバーの一人写りの顔写真を1〜3枚
手順1: 共有フォルダをマイドライブに追加する
共有された写真フォルダはそのままだとColabから直接パスで参照しづらいので、ショートカットをマイドライブに追加しておきます。コピーではないので容量は消費しません。
共有フォルダを開き、フォルダ名の右クリック(またはパンくずから)→「ショートカットをドライブに追加」→「マイドライブ」を選んで追加します。
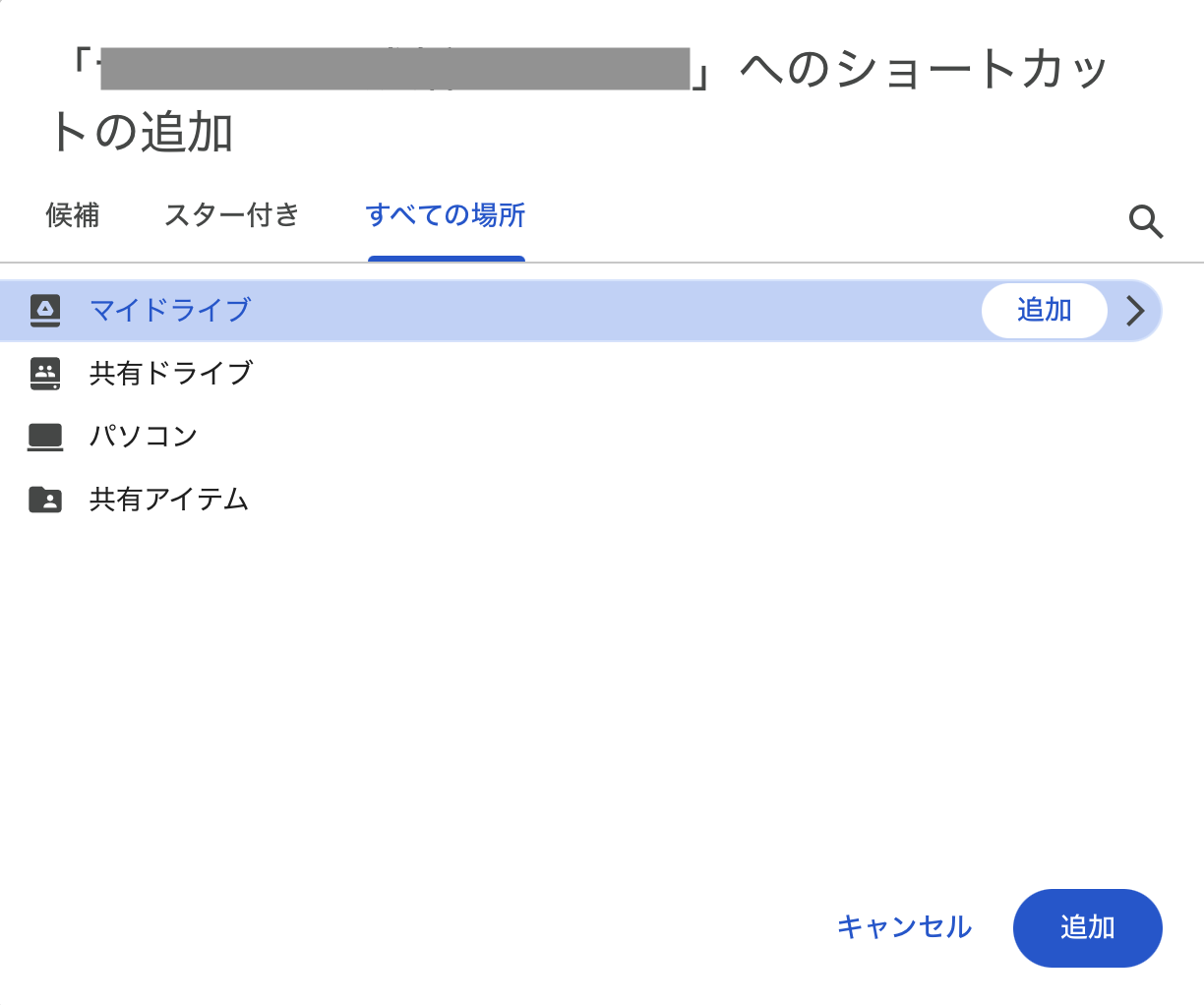
手順2: Google Colabを起動してドライブをマウント
colab.research.google.com で新しいノートブックを作成します。左のサイドバーにあるフォルダアイコンをクリックし、「Googleドライブをマウント」ボタンを押すと、認証ダイアログが立ち上がります。
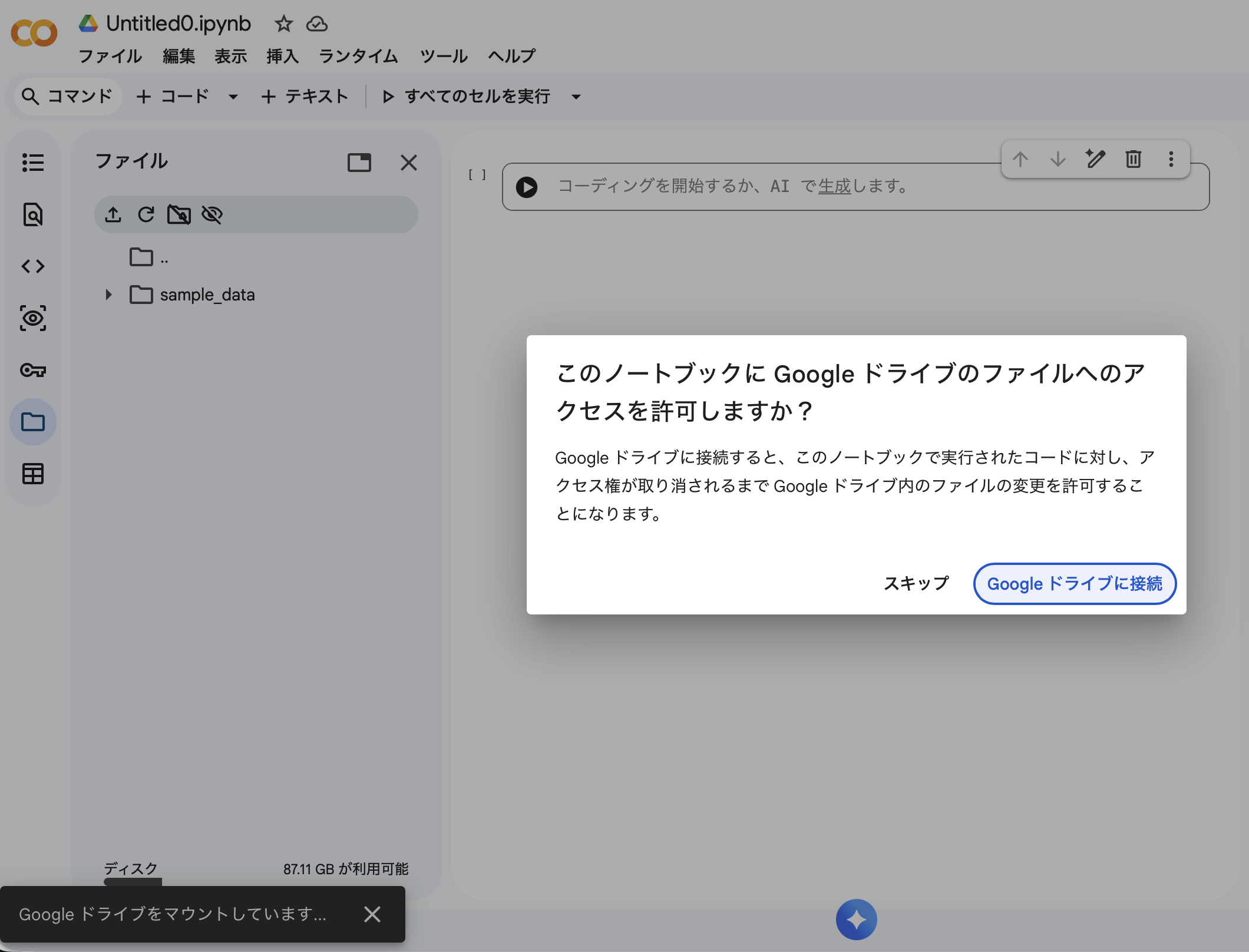
許可するとセルに以下のコードが自動挿入されるので、そのままShift+Enterで実行します。
from google.colab import drive
drive.mount('/content/drive')
左のファイルツリーに drive/MyDrive/ 以下が見えれば成功です。
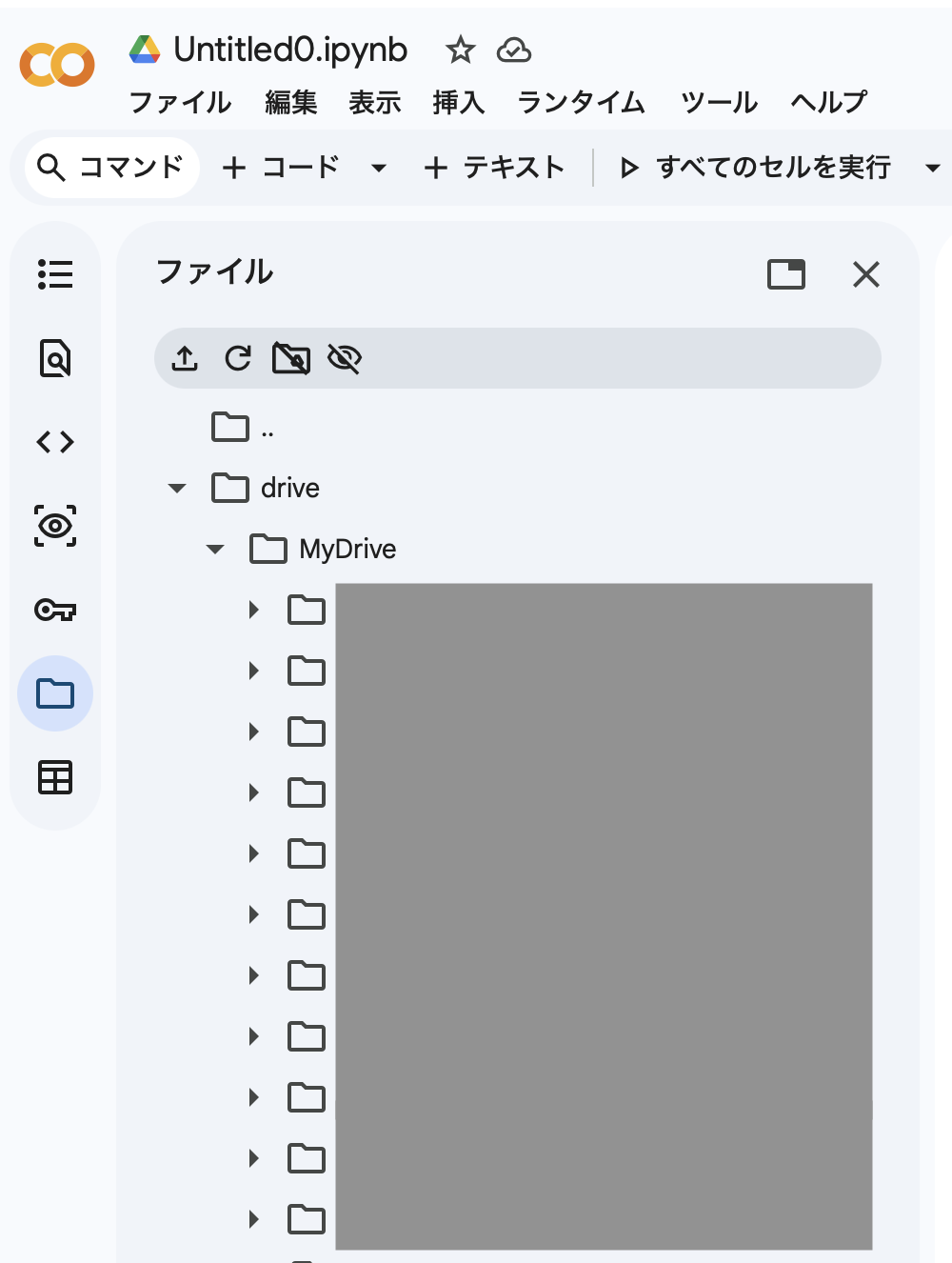
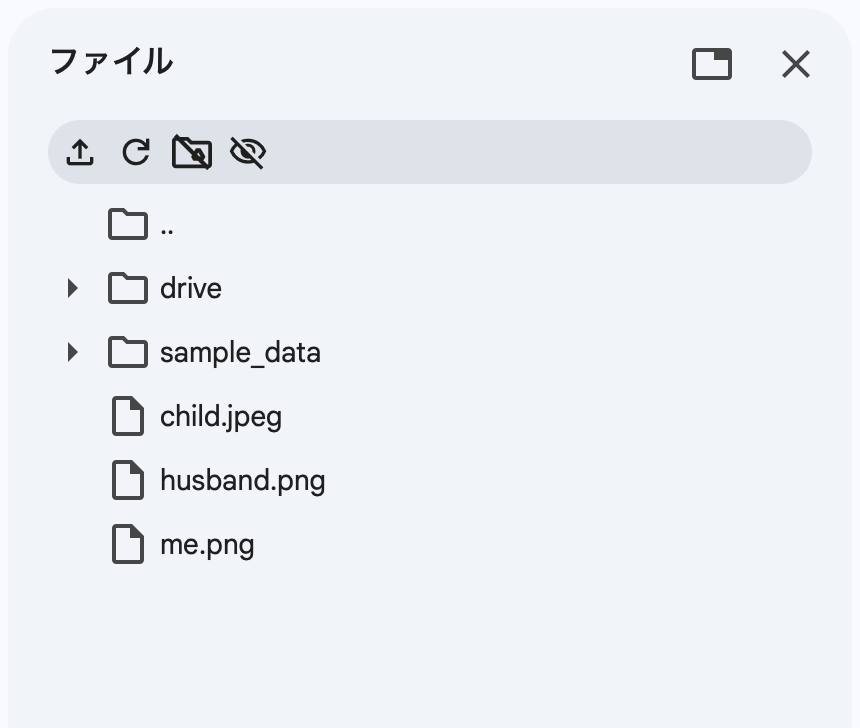
手順3: 参照写真をアップロード
家族メンバーの一人写りの顔写真を、Colabの一時ストレージに直接アップロードします。ファイルパネルの「↑」ボタンから3枚を選択し、me.png husband.png child.jpeg のような分かりやすい名前にしておくと後が楽です。
/content/ というColabセッション専用の一時ストレージです。ノートブックを閉じてしばらくすると(無操作で90分・最大12時間)セッションが切れて、ここに置いたファイルは消えます。 残しておきたい場合は /content/drive/MyDrive/ 配下に置けばDriveに永続化されます。今回は1セッション内で使い切るので一時領域で十分です。参照写真は一人写りの顔写真にしてください。グループ写真を渡してしまうと、写り込んだ他人の顔も「参照」として登録されてしまい、誤検出が一気に増えます。一人ずつくっきり写った写真がない場合は、スマホのギャラリーで顔部分だけスクショを撮ってアップロードすると簡単です。
手順4: face_recognition をインストール
ここで2つ目のセルを作成します。ノートブック左上の「+ コード」ボタンをクリックすると新しいセルが追加されます。そこに以下を貼り付けて実行します。
!pip install face_recognition -q
! はColabでシェルコマンドを実行するための記号です。私は最初これをMacのターミナルに打ち込んでしまい、zsh: command not found: pip と出て一瞬考え込みました。! 付きのコマンドはColabのセルで実行するものと覚えておけば回避できます。インストールには内部でビルドが走るため5〜10分かかります。Building wheel for face-recognition-models (setup.py) ... done まで進めば完了です。

手順5: 抽出スクリプトを実行
さらに「+ コード」で3つ目のセルを追加し、以下のコードをコピペして実行します。PHOTO_DIR は実際のフォルダ名に合わせて書き換えてください。
import face_recognition, os, shutil
from pathlib import Path
PHOTO_DIR = "/content/drive/MyDrive/共有フォルダ名"
OUTPUT_DIR = "/content/drive/MyDrive/抽出済み"
REF_PHOTOS = ["/content/me.png", "/content/husband.png", "/content/child.jpeg"]
TOLERANCE = 0.45
ref_encodings = []
for p in REF_PHOTOS:
img = face_recognition.load_image_file(p)
encs = face_recognition.face_encodings(img)
ref_encodings.extend(encs)
print(f"{Path(p).name}: {len(encs)}件の顔を登録")
Path(OUTPUT_DIR).mkdir(parents=True, exist_ok=True)
photos = [p for p in Path(PHOTO_DIR).glob("*")
if p.suffix.lower() in [".jpg", ".jpeg", ".png"]]
print(f"{len(photos)}枚を処理します...\n")
matched = 0
for photo in photos:
try:
img = face_recognition.load_image_file(str(photo))
faces = face_recognition.face_encodings(img)
hit = any(
any(face_recognition.compare_faces(ref_encodings, f, tolerance=TOLERANCE))
for f in faces
)
if hit:
shutil.copy2(str(photo), OUTPUT_DIR)
matched += 1
print(f"✓ {photo.name}")
else:
print(f" {photo.name}(スキップ)")
except Exception as e:
print(f" {photo.name} エラー: {e}")
print(f"\n完了! {matched}/{len(photos)} 枚を抽出")
print(f"保存先: {OUTPUT_DIR}")
TOLERANCE(許容度)の値です。0に近いほど厳しく判定し、1に近いほど緩く判定します。デフォルトは0.6ですが、これだと誤検出が大量に出ます。初期値は0.45あたりから始めて、結果を見ながら微調整する運用がおすすめです。 後述のとおり、私もここで足踏みしました。試行錯誤の記録
1回ではうまくいかず、3回パラメータを変えて実行してみました。
1回目: TOLERANCE=0.55, 参照写真3枚 → 173/235枚(多すぎ)
最初は安全側に倒して TOLERANCE=0.55 でスタート。結果、235枚中173枚が抽出されました。家族が写っているはずの枚数(10枚程度の予想)に対して明らかに多すぎます。
抽出済みフォルダを目視で確認したら、知らない人の写真が大量に紛れていました。同じイベントの参加者は年齢層・服装・撮影条件が似通っていることもあり、0.55では「ちょっと似た顔」を全部拾ってしまうようです。
2回目: TOLERANCE=0.4, 参照写真2枚(こども除外) → 16/235枚(少なすぎ)
次に思い切って TOLERANCE=0.4 まで絞り、さらに精度の不安定なこども(赤ちゃん)の参照写真(child.jpeg)を一旦外して再実行しました。
REF_PHOTOS = ["/content/me.png", "/content/husband.png"]
TOLERANCE = 0.4
結果は 235枚中16枚。今度は逆に絞りすぎました。

ここで一旦、元写真235枚を全部目視で見て「家族が写っている枚数」のグラウンドトゥルースを取りました。実際は14枚でした。
その14枚を今回の抽出結果16枚と突き合わせると:
- 正しく抽出できた: 8枚
- 見逃した: 6枚
- 誤って抽出した(他人): 8枚
精度は50%、再現率は57%という結果になり、両方ともなかなか芳しくない数字でした。原因を整理すると、
- TOLERANCE=0.4は厳しすぎて、横顔・暗所・小さく写った顔を取りこぼしている
- こどもの参照写真を外したため、こどもがメインの構図が拾えなかった
この2点が効いていそうでした。
3回目: TOLERANCE=0.45, 参照写真3枚に戻す → 57/235枚(合格点)
そこでこどもの参照写真を戻し、TOLERANCE を中間の0.45に設定して再実行。
REF_PHOTOS = ["/content/me.png", "/content/husband.png", "/content/child.jpeg"]
TOLERANCE = 0.45
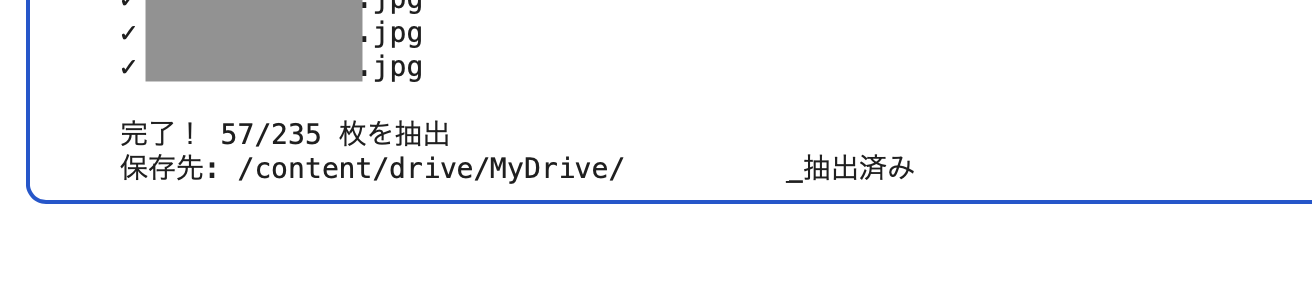
結果は 235枚中57枚を抽出。
| 項目 | 枚数 |
|---|---|
| 実際に家族が写っていた | 14枚 |
| 正しく抽出できた | 12枚 |
| 見逃した | 2枚(ともに横顔) |
| 誤検出(他人を含む) | 45枚 |
再現率は12/14=85%まで改善。誤検出は45枚と多めですが、235枚を全部目視で見るのと比べれば、57枚から最終チェックする手間は4分の1以下です。見逃した2枚はどちらもほぼ真横を向いた横顔で、face_recognition の正面顔学習モデルでは原理的に厳しい部類だと思います。
考察|このスクリプトの「価値」をどう見るか
3回のトライで結果は出ましたが、誤検出45枚・見逃し2枚という数字だけ見ると「精度として微妙」と感じる方もいるかもしれません。ただ、この道具を何のために使ったかを思い出すと、評価の見え方が変わってきます。
元の課題に立ち返る|「235枚を全部見る」をどう減らせたか
そもそも私が解決したかったのは「Driveで共有された大量の写真から、家族が写った数枚を取り出す」という一点でした。これに対して今回得たのは:
- 目視チェックの対象が 235枚 → 57枚(76%削減)
- 57枚に家族写真14枚中12枚が含まれている(再現率85%)
- 残り178枚は「ほぼ家族なし」と機械が判定済み
誤検出45枚が混じっていても、57枚をサムネイル一覧でぱっと眺めて「これは違う」と弾く作業は、235枚を一枚ずつDLして開いて確認するのとは比べものになりません。精度の指標(precision/recall)と、実用上のうれしさは必ずしも一致しないというのが、今回いちばん腑に落ちた部分でした。
見逃した2枚については、念のため残り178枚をサムネイル流し見で確認すれば回収できます。Driveのプレビュー画面なら横スクロールで数十枚まとめて見られるので、これも数分で済みます。「絞り込んだ57枚を精査+残り178枚をざっと流し見」という二段構えにすれば、見逃しのリスクヘッジも兼ねられます。
TOLERANCEの値は「正解」がない
「0.45がベスト」と書きたくなりますが、これは今回の私の条件(参加者数百人規模・室内照明・参照写真の質・登録3名)でたまたまうまく機能した値にすぎません。実際にはこんな要因が複合的に効いてきます。
- 参照写真の枚数・正面度合い・解像度
- 検索対象の写真の撮影条件(明るさ・距離・角度)
- 登録した人数(多いほど誤検出が増えやすい)
- 似た顔の人が現場に多いか少ないか
なので、毎回 0.45を起点に試して、結果を見て上下に動かす という運用ルールを身につける方が、固定値を覚えるより役に立ちます。0.4にしたら見逃しが急増した、0.55にしたら誤検出が急増した、という今回の結果は、いい意味で「振れ幅」を体感できました。
改めてGoogleフォトのすごさを実感
ここまでやってあらためて思ったのは、Googleフォトってすごいんですね……ということでした。普段は何も考えずに「家族の顔」でフィルターをかけているけれど、自分で同じことをやろうとすると参照写真の用意・パラメータ調整・横顔への対応・赤ちゃんへの対応と、いちいち試行錯誤が必要になります。Googleフォトはこれを無料で、しかもクリック1つでこなしてしまうわけで、裏側でどれだけのモデル改良と運用が積まれているのか、想像するだけで気が遠くなります。
ただ、Googleフォトにも弱点はあって、「自分のフォトに取り込んでいない、他人のドライブにある写真」には手が届きません。 今回のように共有された写真をすべてDLしてからフォトに同期して……となると、ストレージが膨らんで効率化の意味が薄れます。Googleフォトが届かないニッチな領域に、Colab + face_recognition の出番がある。 そう位置づけると、ちょうどよく棲み分けが見えてきます。
この仕組みが活きそうな場面
同じやり方は、こんなシーンで使えそうです。
- イベント幹事が共有してくれた集合写真の一括選別:今回のケースそのもの
- 保育園・学校行事の写真共有サービス(共有URLからのDL前段階で絞り込み)
- 旅行先で撮ってもらった大量の集合写真の整理
- 古いHDDやNASの中の家族写真フォルダの棚卸し:Googleフォトに取り込みたい候補を絞る用途
共通するのは「全部見るのは無理。でも完全自動化は精度的に厳しい」という写真整理の困りごとです。手作業100%と全自動の間に、「機械が雑に絞り込んで、人が最後だけ目視する」という第三の選択肢を一つ増やせるのが、今回の仕組みのいちばんの価値かなと思っています。
まとめ
- Google Colab +
face_recognitionで、共有Driveの写真から家族が写ったものだけ自動抽出できます - 235枚→57枚(76%削減)まで絞れれば、最終チェックの負担はかなり軽くなります
- TOLERANCEは0.45前後がスタート地点。固定値ではなく、結果を見ながら上下に動かす運用が現実的です
- 参照写真は一人写り、できれば正面顔のものを使う
- 完璧は狙わず「機械が雑に絞り込んで、人が最後だけ目視する」と割り切ると気が楽
普段は意識しないGoogleフォトのありがたみを、結果的に実感する機会にもなりました。似たような共有写真整理で足踏みしている方は、ぜひ試してみるのはいかがでしょう。
なお、本記事と同じく「自分用の小さな自動化」シリーズとして、iPhoneヘルスケアの歩数データをCSVに書き出すショートカット や GASでGmailを自動ラベリングした話 も書いていますので、よかったら覗いてみてください。
おまけ|あらかじめお断り
「3回も試行錯誤した時間で、235枚を全部眺めて手作業で選別する方が早かったのでは?」というご指摘につきましては、当ブログでは一切受け付けておりません。やってみて初めて分かることに価値があるという大前提のもと書かれている記事ですので、何卒ご容赦ください。次回また同じような共有写真が来たときには、TOLERANCEを0.45に設定するだけで2分で処理が終わるはずなので、その時に元を取る予定です。


コメント